1 773 people
17 conferences
110 hours
13 speakers
Why us?
These courses are for you if you:



Frontend Developer
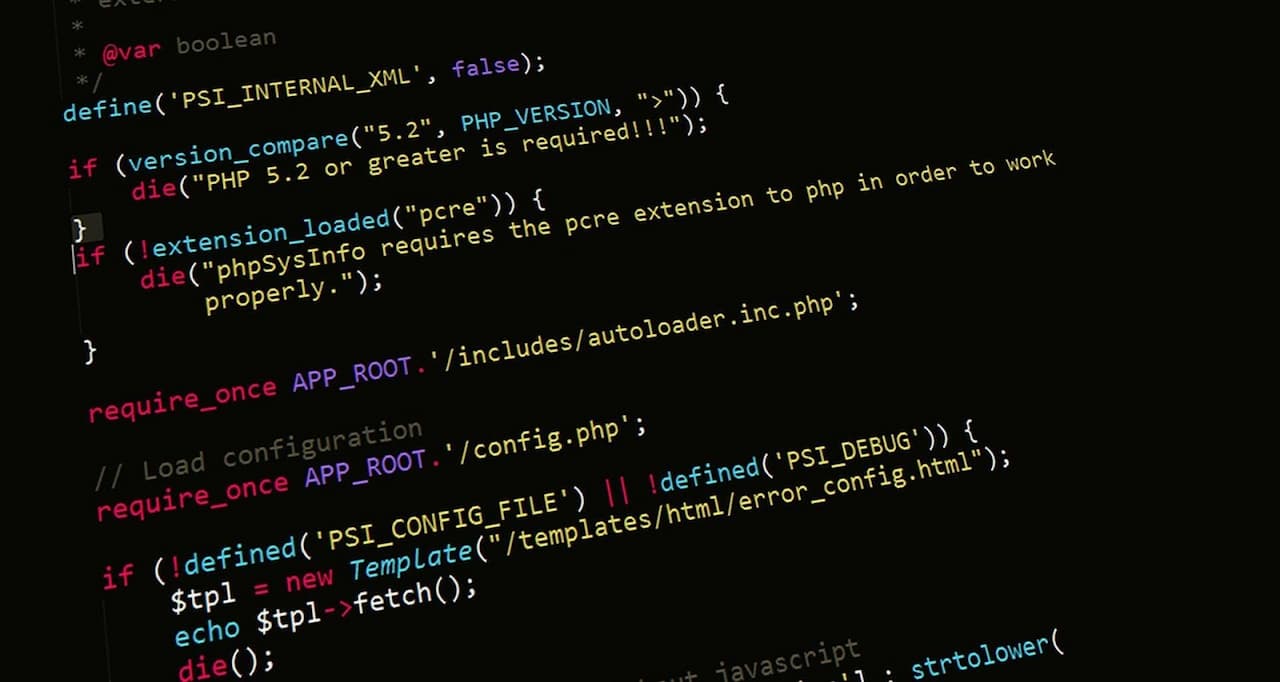
PHP Developer

Join us. It will only take a minute.
Our Speakers

Tony Ellis

Matthew Carroll

Erika Copeland

Kari Nunez
A little bit about us in percentages
Writeanessayfor.me is a new concept in academic writing! Order quality and original papers of any type and complexity on time and at affordable prices!

Tips.GG aggregates tons of statistics about CS:GO, LoL, Valorant esports disciplines. Check the latest esports results of League for Legends matches on our website.

Our innovative integration of cutting-edge IT technologies and advanced gamification techniques has culminated in the creation of the Aviator game. This unique product has rapidly gained acclaim and a strong foothold within the gaming industry, not only across India but globally.
OCrypto Canada’s best crypto exchange rating will help you out with picking the right crypto trading platform.

Parimatch – the best betting site , just choose your best and win

Face difficulties with your homework? Get programming assignment help from experts within any topic and discipline.

The best way to enjoy online casino gambling when blocked by the GamStop self-exclusion program is to visit and register with casinos not on GamStop.

A €25 bonus at an online casino can provide players with additional funds to play, potentially increasing their chances of winning without having to spend as much of their own money.
 Avenga offers comprehensive IT consulting services that help organizations ideate, validate, design, engineer, test, deploy, and maintain sophisticated technology solutions.
Avenga offers comprehensive IT consulting services that help organizations ideate, validate, design, engineer, test, deploy, and maintain sophisticated technology solutions.
87%
got a job after our training
93%
positive reviews
91%
of respondents found our courses useful
Latest news